
 |
početna |
|
predgovor |
|
uvod |
|
o području |
|
opis sustava |
|
implementacija |
|
višejezičnost |
|
zaključak |
|
literatura |
|
o studentima |
>> Implementacija >> Ekstrakcija Eurovoc deskriptora iz dokumenta >> Implementacija ekstrakcije
Nekoliko detalja razlikuje samu implementaciju ekstrakcije od formalne definicije. Tekst dokumenta razdvojen je u više interpunkcijom omeđenih dijelova. Ekstrakcija se provodi nad svakim dijelom teksta posebno. Za svaki deskriptor pamti se svako njegovo pojavljivanje u tekstu, tako da se kasnije ta informacija može iskoristiti za obilježavanje deskriptora u korisničkom sučelju.
Ekstrakcija deskriptora iz jednog dijela teksta provodi se u dvije faze: prvo se nađu sva pojavljivanja svakog deskriptora, da bi se tek kasnije iskoristila definicija skupa ekstrahiranih deskriptora za odabir onih bitnijih. Implementacija se u ovom dijelu razlikuje od definicije u tome što se ne bira najljeviji najduži deskriptor ako postoji više najdužih, već se bira onaj bliže sredini. Razlog tome jest smanjivanje dubine rekurzije. U degeneriranom bi slučaju prvi način radio sa vremenom.
O(n2),
gdje je n broj riječi, dok je u drugom slučaju složenost algoritma odabira deskriptora u najgorem slučaju
O(n log n).
Nalaženje najdužeg deskriptora mora biti brzo jer postoji blizu 10000 deskriptora i asocijata, te bi naivno traženje zahtijevalo sljedeći broj usporedbi skupova lema:
nd • wd • w
nd – ukupan broj različitih deskriptora ? 10000
wd – prosječan broj riječi po deskriptoru ? 2,3
n – broj riječi u dokumentu
Usporedba dva skupa lema potrebna je da bi se utvrdilo odgovara li riječ iz deskriptora riječi u dokumentu. Ta operacija nije trivijalna operacija (npr. poput aritmetičkog množenja), a broj riječi po dokumentu može biti vrlo velik, pa je ovakvo rješenje neprihvatljivo. Bolje rješenje može se naći pretprocesiranjem popisa deskriptora i asocijata. Generiraju se sve moguće lematizacije svakog deskriptora i asocijata i spremaju u jedinstveni popis (Tablica 2). Traženje deskriptora sada je znatno lakše.
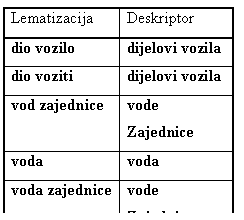
Tablica 2. Sve lematizacije deskriptora "dijelovi vozila", "vode Zajednice" i "voda" stavljaju se u zajednički popis koji je poredan po abecedi. Za svaku moguću lematizaciju pamti se referenca na originalni deskriptor.
Za svaku riječ iz dijela teksta u kojem se vrši pretraga pokušavaju se naći svi deskriptori koji počinju s tom riječi. Krene se "oprezno", tražeći deskriptore duljine jedne riječi, zatim se traže deskriptori duljine dvije riječi, itd. Ako se traži deskriptor duljine n, onda se generiraju sve lematizacije n riječi počevši od trenutne, te se gleda je li ijedna od generiranih lematizacija prefiks neke od lematizacija u listi lematiziranih deskriptora. Ako nijedna generirana lematizacija nije prefiks, nema potrebe za traženjem deskriptora duljine n + 1, a ako lematizacija nije samo prefiks, već odgovara nekoj od lematizacija iz liste lematiziranih deskriptora, onda je deskriptor nađen.

Slika 19. Za svaku riječ pokušavaju se naći svi deskriptori koji počinju sa tom riječi. Zelenom bojom označene su lematizacije koje odgovaraju nekom deskriptoru, žutom bojom su označene lematizacije koje su prefiks barem jednog deskriptora, a crvenom bojom su označene lematizacije koje nisu prefiks nijednog deskriptora.
Ako se provjera je li dana lematizacija prefiks neke od lematizacija u listi lematiziranih deskriptora izvede binarnim pretraživanjem, trajanje te operacije je
O(log nL),
nL – ukupan broj lematizacija svih deskriptora
Broj lematizacija višerječnog izraza eksponencijalna je funkcija ovisna o broju riječi u izrazu, pa bi se mogao očekivati veliki ukupni broj lematizacija svih deskriptora. Na svu sreću, homografija je vrlo rijetka pojava u hrvatskom jeziku, pa je konstanta eksponencijalne funkcije vrlo malena. Također, svi su izrazi vrlo ograničene dužine, pa se i na taj način ograničava broj lematizacija. Ukupan broj lematizacija svih deskriptora manji je od 20000 za hrvatski, tako da je ubrzanje značajno, reda veličine
nd/log2(nL).