
 |
početna |
|
predgovor |
|
uvod |
|
o području |
|
opis sustava |
|
implementacija |
|
višejezičnost |
|
zaključak |
|
literatura |
|
o studentima |
>> Implementacija >> Ekstrakcija kolokacija >> Prijenos na SPID
U prethodnom poglavlju navedeni su načini na koje se mogu ekstrahirati kolokacije iz nekog korpusa. Ovdje ćemo opisati način na koji se te kolokacije koriste da bi upotpunile informacije pomoću kojih indeksator odlučuje kojim će deskriptorima indeksirati dokument.
Kolokacije koje se traže u tekstu ne moraju se nužno sastojati od uzastopnih riječi. Npr. u tekstu „...kamatne stope velikih poslovnih banaka...“ ne bi bila ekstrahirana kolokacija koja se sastoji od 4 riječi „kamatne stope poslovnih banaka“, ako bi se promatrale samo uzastopne riječi. U svrhu toga za ekstrakciju udaljenih kolokacija definiran je kolokacijski prozor. Za kolokacijski prozor definira se širina kolokacijskog prozora M kao broj riječi koje obuhvaća prozor. Svakih N riječi iz kolokacijskog prozora pokušava se spojiti da bi se provjerilo formiraju li tih N riječi kolokaciju.
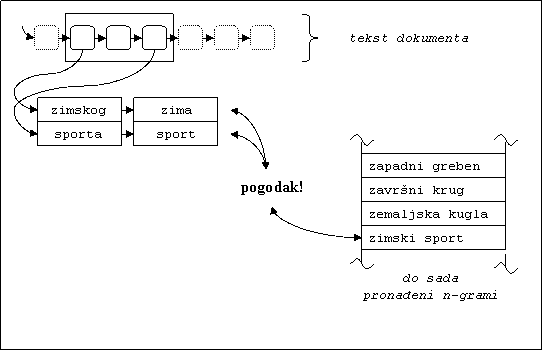
Slika 13. Grafička apstrakcija postupka ekstrakcije n-grama. Uočava se prozor koji obuhvaća tri pojavnice iz dokumenta, od kojih se dvije pokušavaju složiti u n-gram.
Provjera je li nekih N riječi tvori kolokaciju obavlja se u više koraka. U prvom koraku se svaka riječ od odabranih n lematizira (vidi poglavlje 5.6). Kao rezultat lematizacije n-grama dobije se skup
L(n-gram) = L(w1) x L(w2) x ... x L(wn)
gdje je L(wi) skup lema neke riječi, a ? označava kartezijev produkt. U drugom koraku provjeravamo je li n-gram u popisu kolokacija. U slučaju da se n-gram nalazi u popisu kolokacija, tada se frekvencija za tu kolokaciju povećava za jedan i n-gram se sprema u mapu. U mapu se spremaju slijedeće informacije :
• skup L(n-gram)
• skup različnica w1, w2,..., wn
• frekvencija pojavljivanja n-grama
• frekvencija pojavljivanja pojedinog skupa različnica.
Provjera je li n-gram u popisu kolokacija obavlja se tako da se provjeri da li je neki element popisa kolokacija također element skupa L(n-gram).
U nastavku je dan opis algoritma u pseudokodu sličnom programskom jeziku C.
Varijable korištene u pseudokodu:
• Doc – dokument koji se obrađuje
• M – veličina kolokacijskog prozora
• N – veličina n-grama
• ngramSet – niz n-grama
• L – označava skup lema neke riječ
• lematizedNgram – skup n-torki lematiziranih različnica u n-grama
• LargeNgramSet – skup pronađenih n-grama u dokumentu
• CreateNgram – funkcija koja vraća n-grame veličine N unutar kolokacijskog prozora širine M krenuvši od pozicije i u dokumentu
• LematizeWord – funkcija koja vraća skup lema neke različnice
• colocationList – popis kolokacija dobiven ekstrakcijom kolokacija iz korpusa
