
 |
početna |
|
predgovor |
|
uvod |
|
o području |
|
opis sustava |
|
implementacija |
|
višejezičnost |
|
zaključak |
|
literatura |
|
o studentima |
>> Opis sustava SPIS >> Poluautomatski Eurovoc indeksator (PEI) >> Statistika različnica i lema
Na temelju samog teksta dokumenta te dodatnih informacija kodiranih u učitanom XML formatu gradi se unutrašnja struktura podataka koja omogućuje manipuliranje podacima za vrijeme rada sa sustavom. Također, provodi se niz leksičkih i statističkih obrada.
Primjer korisničkog sučelja dan je na slici 4. Nakon inicijalnog procesiranja, vizualna reprezentacija učitanog dokumenta prikazuje se na lijevoj strani korisničkog sučelja. Vizualna reprezentacija generira se koristeći informacije o formatiranju i strukturi samog dokumenta, ugrađene u XML zapis.
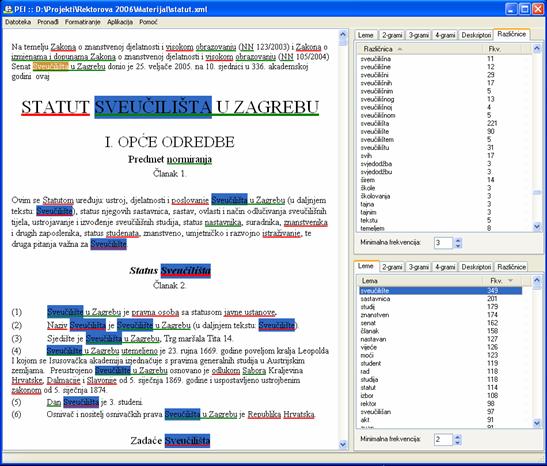
Slika 4. Korisničko sučelje sustava. S lijeve strane prikazana je vizualna reprezentacija učitanog dokumenta (Statut Sveučilišta u Zagrebu), dok su sa desne strane vidljivi rezultati leksičke i statističke obrade. Uočava se brojnost morfoloških različnica leme sveučilište.
Primarni rezultati leksičke obrade i statističke analize dokumenta vidljivi su u desnom dijelu korisničkog sučelja sustava, koji je podijeljen u dva identična dijela. Za svaki dio moguće je neovisno odabrati statističku informaciju koja će biti prikazana. Dostupne su slijedeće statističke informacije:
• skup uređenih parova svih morfoloških pojavnica pronađenih u tekstu dokumenta i pripadnih frekvencija pojavljivanja
• skup uređenih parova lema svih pojavnica pronađenih u dokumentu i pripadnih frekvencija pojavljivanja
• skupovi uređenih parova statistički najznačajnijih bigrama, trigrama i tetragrama pronađenih u dokumentu i pripadnih frekvencija pojavljivanja.
• skupovi uređenih parova svih deskriptora i asocijata pronađenih u dokumentu i pripadnih frekvencija pojavljivanja
Svi skupovi uređenih parova prikazani su u obliku popisa koji je moguće poredati po riječi (pojavnici, lemi, n-gramu odnosno deskriptoru) ili po frekvenciji pojavljivanja, uzlazno ili silazno. Moguće je i označiti sva pojavljivanja odabranog člana popisa.
Unaprijed provedena leksička i sintaktička analiza pruža odlične mogućnosti za vizualno predstavljanje informacija korisniku. Kao što je već spomenuto, uočljivom crvenom bojom pozadine označavaju se pojavljivanja proizvoljne pojavnice ili leme unutar teksta, dok daljnjim pretragama selekcija iterativno prelazi s jednog pojavljivanja na drugo. Ovime je korisniku omogućeno jednostavno proučavanje konteksta u kojem se pojavljuju pojmovi potencijalno bitni za indeksiranje dokumenta.
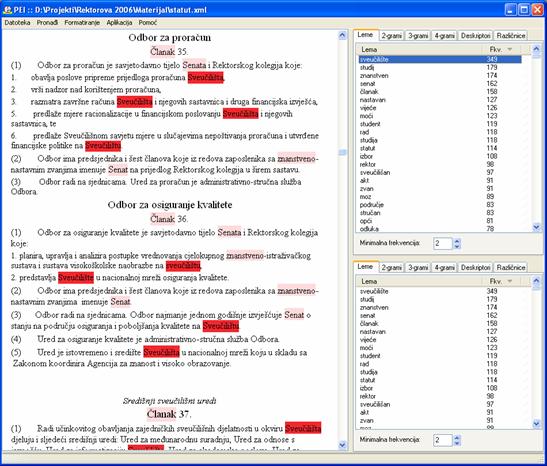
Slika 5. Vizualno naglašavanje pojavnica najčešćih lema. U konkretnom primjeru Statuta Sveučilišta u Zagrebu vidljivo je stavljen naglasak na leme sveučilište, senat i znanstven.
Sustav također omogućuje vizualno naglašavanje najfrekventnijih lema unutar dokumenta, primjer čega je dan na slici 5, kao i sivljenje zaustavnih riječi - leksičkih jedinki sa minimalnim semantičkim značenjem, kao što su veznici, brojevi i slično [4]. Ovakve funkcionalnosti fokusiraju pažnju na statistički relevantne dijelove dokumenta.